Clearing up React Data Management Confusion with Flux, Redux, and Relay
In discussing a recent decision to use Redux for a project, I’ve been asked several times why one would use a Flux-based pattern like Redux now that approaches like Facebook’s Relay or Netflix’s Falcor are available.
Question: Why use Flux or Redux now that Relay is available?
The frequency of the question suggests that there may be some ongoing general confusion about the various data management approaches that are part of a rapidly-evolving ecosystem inspired by React. This post hopes to clear up confusion for product owners, designers, or engineers who might not already be familiar with data management in the React ecosystem.
The Short Answer
- Flux/Redux are client-side only data management patterns, completely decoupled from your API service, suitable for situations where you’re doing design/dev on front-end only, and suitable for use with any backend.
- Relay/Falcor are end-to-end data management patterns, only suitable for situations where you’re designing an end-to-end application. Can have big implications on your backend - e.g. Relay requires a GraphQL-based API service.
Background on React and Web Application Data Management
React, a Javascript library from Facebook, has taken center-stage in client-side web development this year. It provides an interface to the DOM, the browser’s HTML content layer, that gives developers a simple, powerful model for managing the user experience: compose the UI from components that get updated completely (as opposed to making individual changes) whenever relevant application state changes occur. Any events - whether new data from the server or an action from the user - that impact the UI, are to be handled by some data management layer (hence the need for Flux - see below), applied directly to the application state, triggering the view layer to update completely. This unidirectional flow radically simplifies the development challenge compared to alternative approaches that involve making individual UI updates in response to events. React provides “diffing” functionality that makes this otherwise impractical approach highly performant.
React with Basic Client-Side Data Management
React isn’t a complete client-side framework like Angular or Ember. It only addresses a single, very important aspect of the application, it’s view layer: given the data that the UI needs at a given time, how does the application appropriately update the UI to reflect this data. React’s approach to the view layer has proven so compelling that this approach is quickly becoming the standard for client-side web development, driving a massive shift toward adoption of React itself and causing the other major frameworks to adopt some variation of its unidirectional data flow with DOM diffing model.
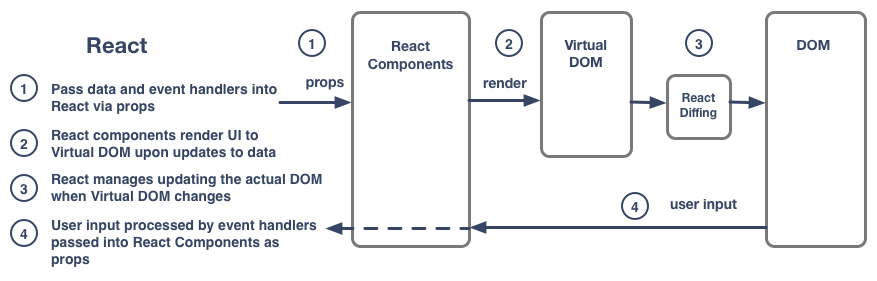
Because it handles only the view layer, developers compliment React with other technologies to round out client-side functionality, particularly routing and data management. The developments in the data management area are especially interesting. They fall into two categories: client-only and end-to-end.
React with Flux/Redux Client-side Data Management
The React community began to consolidate around a pattern for data management called Flux, also promoted by Facebook. With similarities to existing software design patterns like CQRS, Flux isn’t entirely new, but it brought a new way of thinking about data to client-side web development.
The main value of the Flux pattern is that it combines with the open-circuit unidirectional flow of React to create a closed-circuit unidirectional flow suitable for building complete client-side applications.
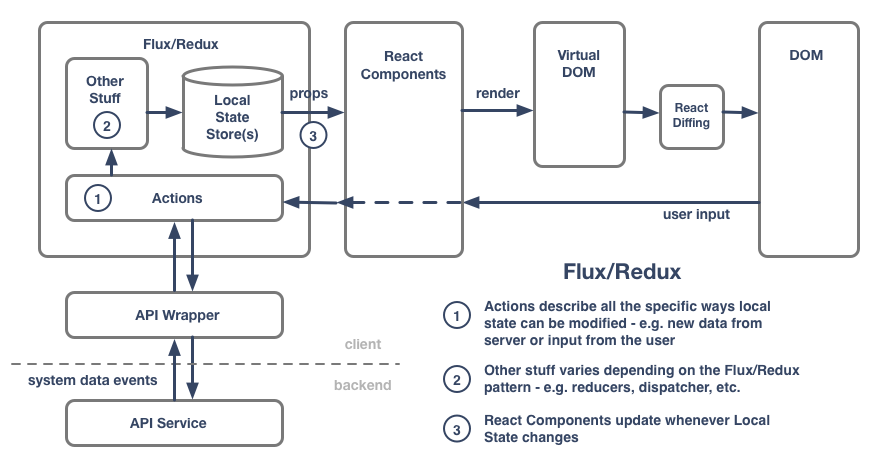
The “cartoon” overviews of Flux and Redux more fully explain these patterns - e.g. expanding on the “Other Stuff” piece this diagram doesn’t cover.
React with Relay End-to-End Data Management
With Relay, and a similar middleware library from Netflix called Falcor, we get end-to-end data management frameworks oriented toward the React ecosystem. They provide standard functionality for synchronizing data between the client and the backend, potentially reducing the burden on front-end developers relative to the Flux/Redux scenario. We’ll look a bit at Relay and leave Falcor for another time.
As mentioned above, Relay is an end-to-end approach, meaning it has major implications on the backend, specifically that the API implement GraphQL. This is significant issue for many teams who may have existing REST APIs or who may favor REST as a design pattern for APIs moving forward.
Relay self-describes as a framework for “declarative data fetching”. By declaring only what data is to be fetched, the traditional engineering effort associated with developing how the data is to be fetched is minimized. A more maintainable, less fragile system can be built that reduces ongoing engineering effort as well. Relay emphasizes that data declarations be made at a UI component level, which encourages effective front-end modularization as a weapon against complexity and overall cost. Relay’s cache management is a key example of logic that might otherwise require significant engineering effort.
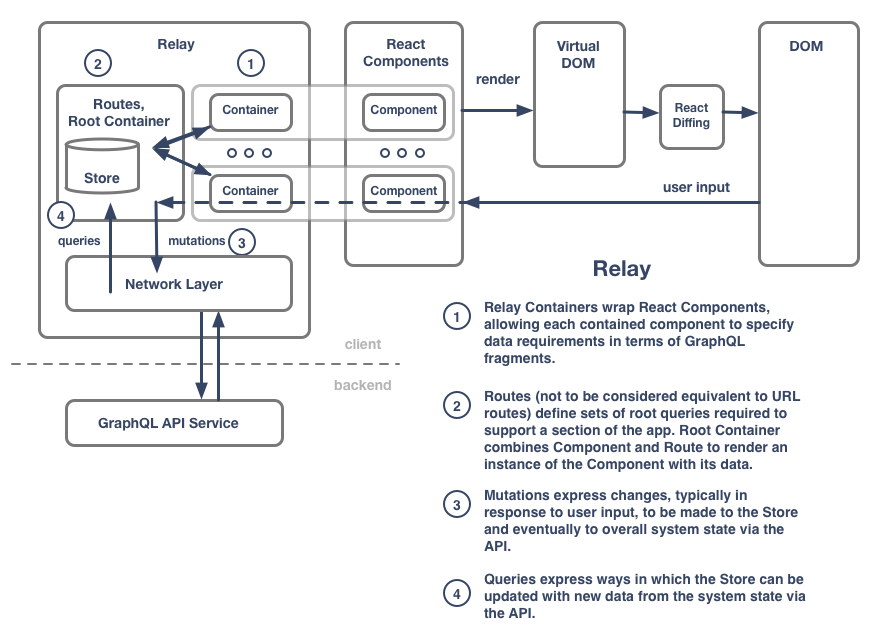
For teams who are able to adopt GraphQL and are thus eligible to use Relay, there’s big potential for benefits. The main benefit for most projects is that the Relay-GraphQL combination minimizes the need for developing one-off functionality in the “API Wrapper” piece of the Flux/Redux scenario. As apps evolve, this functionality can accrue a lot of complexity, with engineering teams continually re-inventing a wheel that’s not typically at the heart of the domain their app addresses.
blog comments powered by Disqus